glibc 2.23
fastbin_dup
2.23的fastbin dup不用考虑tcache的影响,因为还没引入
fastbin_dup使用doublefree的方法,但是要注意不能连续free同一个。
没有doublefree的检查是因为free后后一个chunk的prev_in_use位不会被重置。
操作流程
void * a = malloc(8); |
这时候a控制的是一个free了且malloc了的块,通过控制fd指针来实现任意写。/
fastbin_dup_consolidate
背后的机制是,当从largebin里拿东西的时候,会先尝试把fastbin清掉
ctf-wiki是这么说的:
其实在 large bin 中并没有直接去扫描对应 bin 中的 chunk,而是先利用 malloc_consolidate(参见 malloc_state 相关函数) 函数处理 fast bin 中的 chunk,将有可能能够合并的 chunk 先进行合并后放到 unsorted bin 中,不能够合并的就直接放到 unsorted bin 中,然后再在下面的大循环中进行相应的处理。为什么不直接从相应的 bin 中取出 large chunk 呢?这是 ptmalloc 的机制,它会在分配 large chunk 之前对堆中碎片 chunk 进行合并,以便减少堆中的碎片。
这就给我们有可乘之机。
一个利用策略是,如果程序可以进行double free 但是只能写free前的chunk,可以通过这个方法,
通过double-free和malloc来实现use-after-free。思想在于合并时的指针被程序认为单纯是malloc的。而free掉的那个也是同一个指针,但是malloc的那个指针程序没有标记。
操作流程:
void * p1 = malloc(1,0x40) //fastbin大小 |
从效果上看,p3已经完全是虚假的了,可以覆盖后面一堆chunk。
第二个利用策略是,通过无法合并的fastbin进入unsorted bin 的机制,来产生一个又是fast bin又是unsorted bin 的 chunk
注意再次拿的时候会先从fastbin拿。同样目的是构造use-after-free
流程:
void *p1 = malloc(0x40) |
fastbin_dup_into_stack
fastbin_dup的延申,讲述如何进行任意写入。
首先是之前提到的double_free
流程:
void * a = malloc(8); |
这时候,a的位置被double_free的。通过修改fd指针,使得下一个chunk指向栈上。
2.23 malloc取出fastbin时,存在安全检查:需要malloc的size的值和当前bin的大小一致。
因此栈上的值需要自己提前写入
然后malloc两次即可写到栈上。
这个方法还可以写到main_arena,那个位置有个0x71可以利用。
unsafe unlink
利用基本条件:有一个明确位置的指针,指向可以调用unlink的区域。且那个区域存在一byte溢出0的漏洞。
通常在利用后还需要重新覆盖原指针,实现控制任意位置。
首先要关注的是unlink。在unsafe_unlink中,着通常以合并的形式发生。
只有在非fastbin时,才会触发unlink。这时候考虑合并低地址、合并高地址,合并topchunk。
通常我们的利用方法是合并低地址,且低地址的位置用的是fake chunk。因为unlink操作到的chunk指针是需要指到header的,
但是我们拥有的指针却指到data,因此我们要在data位置构造出header。
前向合并代码
/* consolidate backward */ |
再看unlink代码
|
可以看到,除非是largebin,不然就不会有大小检查。甚至不会检查free掉的东西是否真的在bin中。这时候就能理解为什么fastbinfree时不会把后面的prev_inuse变成0了。不然就会把fastbinunlink,真有点石山代码的意思。不过也有可能是为了更快运行。
largebin最小需要0x7F0,因此基本上不用考虑。
目前的chunk结构(构造完fake chunk ,且溢出了一个byte)。 chunk大小都使用了0x90
| name | data | data |
|---|---|---|
| chunk0 | ?????? | 0x91 |
| fakechunk | ???? | ???? |
| fd=ptr-0x18 | bk=ptr-0x10 | |
| ………… | ………… | ………… |
| chunk1 | 0x80 | 0x90 |
| …… | …… | …… |
最后更新的步骤,导致ptr变成data里的fd,也就是ptr-0x18于是就可以修改任何地址或者读取任何地址。
house of spirit
构造虚假chunk,free后malloc实现在栈上写入的能力。
基本没什么要注意的,一点是必须malloc过,不然根本没有初始化过heap的空间。
还有就是下一个chunk的size需要符合堆的大小0x10到128kb
poison null byte
存在一个溢出null byte时,同时没有uaf时可以使用。并且这个null byte需要能溢出到已经malloc过的chunk。
需要注意的是,被溢出覆盖到的chunk的大小不能是0x100的倍数。(这样才能做到防止prev_inuse被修改,同时保证可以伪造prev_size)
操作流程
void * a,*b,*c,*d; |
overlapping_chunks_1
条件: 存在heap overflow 可以污染metadata
利用非常简单
利用了unsorted bin正好时不存在检查
intptr_t *p1 , *p2 , *p3 , *p4; |
overlapping_chunks_2
Nonadjacent Free Chunk Consolidation Attack
同样也是利用了unsorted bin正好时不存在检查,
事实上 在 2.23版本甚至更高版本,chunk 4 都没什么用,不知道这么做目的是什么,可能是为了后续利用。
流程 :
malloc 5个1000大小chunk
free 4
覆盖2chunk size 变成2+3
free 2
malloc 2000 存储在6
6与3重合。
unsortedbin attack
此攻击可以把一个大数写入任意位置,为后续攻击做准备,比如将global_max_fast改成一个大数,然后可以进行fast_dup等攻击,
这里利用了正好大小的unsorted bin 取出时不经过任何安全检查。
假设要修改的位置地址ptr
chunk为p
修改p->bk = (unsigned long *)ptr-2
则脱出双链表时
ptr-2+2也就是fd的位置会变成p->fd 为main_arena附近的值。
largebin attack
largebin 要大于1024字节。双向循环链表,先进先出。
作用和unsorted bin attack 差不多
但是利用的特性比较巧妙。
这里直接复制了 https://wiki.wgpsec.org/knowledge/ctf/how2heap.html 的流程
|
利用在分配时,会先把unsorted bin闲置块整理的特性和uaf漏洞。
同时 glibc的逻辑貌似一直是先插入再断链,断链的过程才真正修改了指针,也就是说 修改的是 p3->bk->fd p3->bk_nextsize->fd_nextsize
p3->bk p3->bk_nextsize就是p2->bk p2->bk_nextsize 因此才会那样修改。
这里要注意的是 如果只有一个大小相同的块,bk 和 bk_nextsize作用是等同的。
house of lore
在双向链表完整性检查存在的情况下依然可用
用这个方法可以在栈上任意写入.
利用的是伪造bk指针的方法。smallbin是先进先出的,因此它存在的安全检查会着重考虑p->bk->fd是不是本身。并且还有个有意思的事情是,他的脱链非常不安全。
他的脱链过程就是把head->bk 设置为 p->bk 、 把 p->bk->fd 设置为head
也就是说 即使head->fd的值存在错误,也不会影响程序运行。
并且 2.23中从smallbin拿出来根本不过size检查。
house of lore利用伪造的方法绕过这个检查
how2heap的方法是在栈上构造了两块 虽然不知道有什么用 但这里就按他的来
过程
/* |
看着挺复杂 概括起来却没多少
栈上两个块
| name | value |
|---|---|
| p2 | 0 |
| 0 | |
| fd | &p1 |
| bk | 0 |
| p1 | 0 |
| 0 | |
| fd | victim |
| bk | &p2 |
堆上构造两个块
一个0x100大小 正好smallbin
再弄一个大的0x1000防止合并
free 掉这个smallbin 把bk指针覆盖成&p1
然后smallbin链表结构就会变成下图
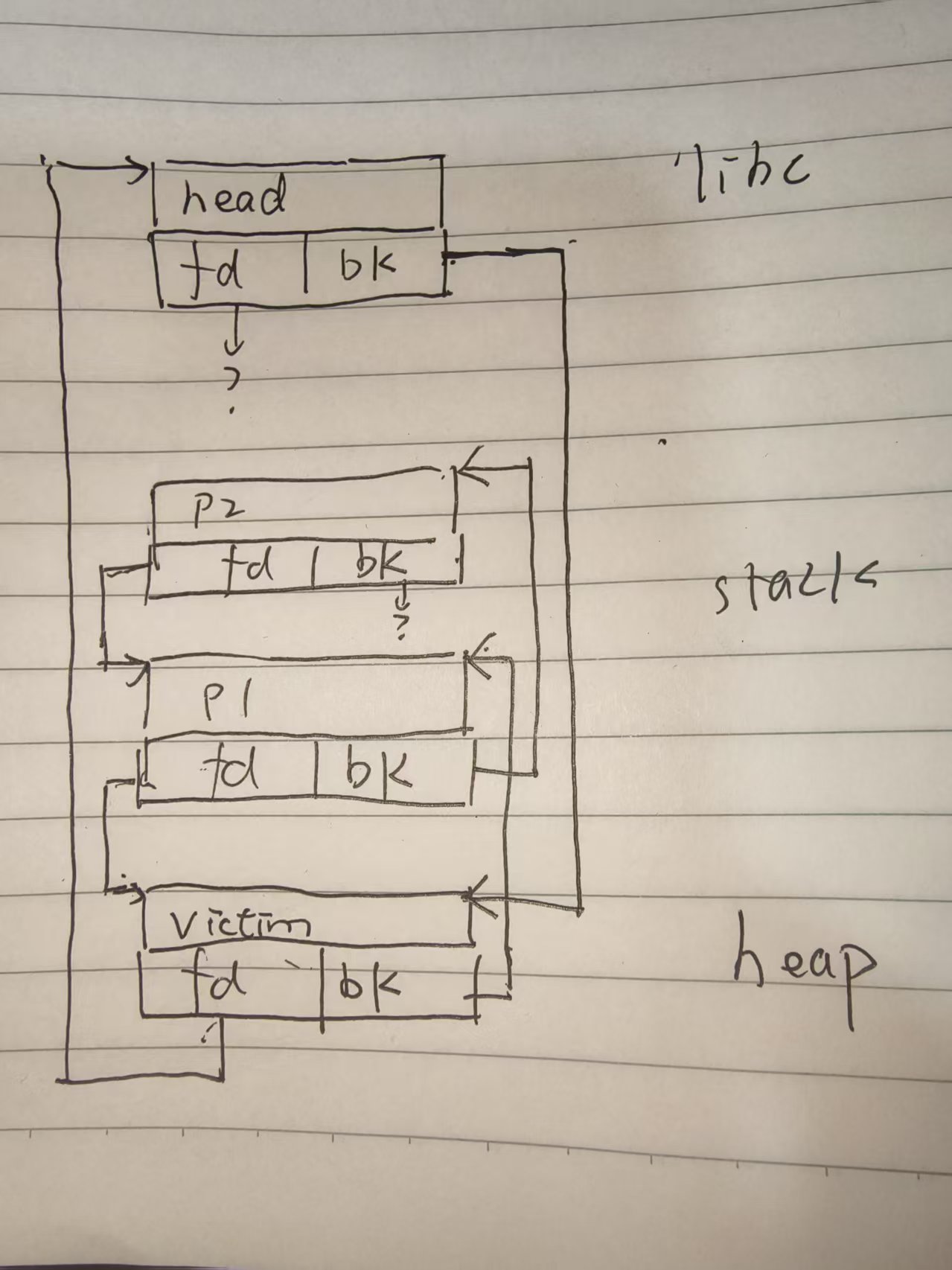
可以看到 head 到p2中间的部分是完全不用管的 这是smallchunk不安全性导致的。
然后先malloc 0x1200
使得unsorted bin 整理到 smallbin
然后再malloc 0x100 两次即可在栈上溢出
mmap_overlapping_chunks
让mmap出的块进行重叠
这个漏洞所有版本可用
mmap_threshold(默认 128KB)
当申请的内存 ≥ mmap_threshold 时,GLibC 会直接通过 mmap 系统调用分配内存(而非堆管理器)。
释放时(free),这类内存会立即通过 munmap 归还系统,不会进入堆缓存。
动态调整的阈值
若程序频繁申请大内存(但 ≤ 当前 mmap_threshold),GLibC 会逐步 提高阈值(上限为 DEFAULT_MMAP_THRESHOLD_MAX,通常 32MB/64MB)。
通过 mallopt(M_MMAP_THRESHOLD, size) 可手动调整。
mmap分配的内存 释放时也不会进入 bins 而是 用munmap系统调用 直接返回给kernel
mmap chunk在标记在第二个bit
对于size 字段 表示当前内存块实际大小,要求页对齐 通常是4kb对齐
prev_size字段 不用于记录前一个内存块的大小 ,而是记录这个mmap块的剩余空间 (多余分配的)
free时存在页对齐检查,同时没有合并操作
分配时 通常在libc地址前面 heap区域后面 并且是从高地址向低地址的顺序分配
过程
|
先 malloc 0x10大小的普通块 不清楚有什么用 估计是初始化heap 空间?
malloc 3个 0x100000大小的块,程序说明里说第一个分配到了 libc的高位 但事实上
我搜到的资料里面他是分配在libc地位的 不管如何 分配三个总不会出问题
第三个是紧接着第二个的,这时候我们修改三的size为2+3 free 掉3
然后malloc一个更大的0x300000 因为 mmapthreshold 已经被调整到了0x202000 再小于的话会变成正常的堆
然后就可以获得一个覆盖到3 2 的大的块
house of force
<2.29版本可用
这个漏洞在有aslr时仍然可以使用,但是需要关闭RELRO 因为要覆盖got表
通过覆盖top chunk 来使得malloc返回一个任意的地址。
是一个非常暴力的利用方式
用起来也很简单。
先分配一个任意大小的chunk
然后覆盖top chunk的size 可以直接写成-1
然后计算地址 直接malloc一个贼大的空间到目标位置
这里不会被mmap干扰,因为top chunk size改了 只要小于这个大小 都会分配再heap上
。
house of einherjar
利用了一个off-by-one overflow 相比posion null byte 更强大 但是额外需要能够泄露堆地址。或者是能够伪造虚假堆块的地址,
流程:
目标位置伪造一块0x100大小的块 。
fd bk fd_nextsize bk_nextsize 都指向本身以绕过检查
prev_size 需要和本身相同 并且为not used 但我不知道有什么用 大佬的博客说并没有伪造的必要
在堆上 申请三个堆块
a = (uint8_t*) malloc(0x38); // 需要有off_one_byte 用来覆盖 b 的prev_in_use
b = (uint8_t*) malloc(0xf8); // 总大小0x100 防止off_one_byte 导致的大小不对
c = (uint8_t*) malloc(0x38); // 防止和top chunk 合并
之后计算伪造的堆块和b的地址差 写入 prev_size即可 通常这需要用到补码,因为heap一般在stack之前。
再malloc(0x200) 就能在目标位置分配chunk
sysmalloc int free
sysmalloc允许我们free() top chunk 创造出一个几乎任意的bins
可以用于在不直接调用free() 的情况下破坏堆结构
堆增长时,如果top_chunk无法被合并,sysmalloc会调用_int_free 来释放 top_chunk
在House of Orange 和 House of Tangerine中都有用到
流程:
- initial malloc ,后续要用来让top_chunk崩溃
how2heap中malloc了0xe60的大小 - 污染top_chunk 的size段,注意控制它的终点是page_aligned 的 ,也就是是0x1000的倍数
- 创建一个比目前修改过的topchunk还要更大的块,这会欺骗堆增长,同时导致原来top_chunk的位置被free。但是到对齐位置最后0x20会是一个FENCEPOST
----- 0x56563f850020 ---- |
重新malloc 会从FENCEPOST后面开始分配。
house_of_orange
利用堆溢出漏洞来篡改 _IO_list_all指针
需要事先存在堆和libc地址的泄露。
同时需要存在一个能覆盖topchunk数据的heap溢出。
本例中的winner用于模拟system函数的地址已知的情况。
当请求小于0x21000,且大于top_chunk大小,就会产生topchunk的扩展
该技术已在 glibc 2.26 版本中通过修改 malloc_printerr 的行为被移除, 新版本不再调用 _IO_flush_all_lockp 函数。对应提交:91e7cf982d0104f0e71770f5ae8e3faf352dea9f
自 glibc 2.24 起,_IO_FILE 虚函数表(vtable)会经过白名单验证,这使得该漏洞利用方式失效。
流程:
- 申请一个heap , p1 = malloc(0x400-16); heap通常从0x21000的top chunk中分出来,因此余下0x20c00的空间。加上PREV_INUSE,就是0x20c01
根据topchunk的性质,topchunk始终满足下列条件
- topchunk的结尾永远是页对齐的。
- topchunk的prev_inuse永远被设置。
伪造topchunk 为了满足上述条件,我们把topchunk大小伪造成 0xc00 | PREV_INUSE。
申请一个大于topchunk大小的块 。程序会尝试扩展top chunk ,但是sysmalloc认为原来的top结尾没变,这就导致中间出现一堆空缺。 同时 修改的topchunk会被free掉,申请的p2会在中间的一个0x1000对齐的页开始
之后是第二阶段,我们要尝试覆盖原先被free 的top chunk部分的fd和bk指针进行利用
这种攻击手法极为精妙,它直接利用了 libc 在检测到堆异常时触发的 abort 调用流程。当 abort 被触发时,系统会通过调用 _IO_flush_all_lockp 来刷新所有文件指针,最终遍历 _IO_list_all 中的链表并对每个节点执行 _IO_OVERFLOW 操作。
这种攻击的核心思路是:通过伪造一个文件指针来覆盖 _IO_list_all 指针,其中: 将伪造指针的 _IO_OVERFLOW 位置指向 system 函数,前8字节设置为 ‘/bin/sh’ .这样当调用 _IO_OVERFLOW(fp, EOF) 时,实际会执行 system(‘/bin/sh’)。
通过已经释放的堆块,我们可以获得libc地址,也就可以计算出_IO_list_all的地址,计算出这个地址后 我们把 p(free 的top )->bk设为_IO_list_all-0x10 然后让fd不变,这就可以让_IO_list_all的前八个字节变成”/bin/sh”的指针.
把p的size篡改成0x61 ,这使得它进出main_arena的特定位置 方便之后进行IO-file 利用 具体不细说
接下来伪造来满足约束条件。
fp->_mode <=0 && fp->_IO_write_ptr>fp->_IO_write_base
_mode 偏移0xc0 base偏移 0x20设置为2 ptr 偏移0x28 设置为3改写jump table jump_table 位于 &top[12] (自己选的); jump_table[3] = & winner.
top+0xd8 设置为jump_table的指针 这个是固定的。
malloc(10); 前面由于伪造了p的size 会触发错误
house of roman
house of roman 可以在没有 其他信息泄露的前提下进行堆利用
也就是说 过程中用到的基本是偏移量
分三个阶段进行:
- 获取__malloc_hook :
- 构造fastbin链: ptr_to_chunk -> ptr_to_libc
- 通过相对偏移量 : 部分覆盖 ,将ptr_to_libc 指向 __malloc_hook
- 对__malloc_hook 进行unsortedbin_attack:
- 通过相对偏移量覆盖修改chunk->bk指针
- 将libc的值写入到__malloc_hook
- 劫持控制流:
- 对_malloc_hook的值进行最后一次的相对偏移覆盖,使得它指向目标函数
- 调用malloc获得shell:
这个技术的代价是需要暴力破解12bits的随机值.
利用的前提条件是能够通过漏洞修改fastbin或者unsortedbin的指针同时能够精准控制内存分配的大小和释放操作。
第一阶段:
uint8_t* fastbin_victim = malloc(0x60);
malloc(0x80);
uint8_t* main_arena_use = malloc(0x80);
uint8_t* relative_offset_heap = malloc(0x60);
free(main_arena_use);
free后的这个块的fd与bk指针会指向main_arena + 0x68
uint8_t* fake_libc_chunk = malloc(0x60);
long long __malloc_hook = ((long*)fake_libc_chunk)[0] - 0xe8;
这样就成功获取了__malloc_hook地址.
free掉relative_offset_heap 这会在 fastbin_victim的fd槽位中放入一个指针以便后续使用。
free(fastbin_victim);
后续需要进行UAF利用,另外,fd的偏移是0x190.
现在进行相对覆盖,目前的堆如下:
0x0: fastbin_victim freed |
fastbin: fastbin_victim -> relative_offset_heap |
现在开始部分覆盖fastbin_victim的fd指针(最后一位从0x90变成0x00),控制它指向fake_libc_chunk
fastbin_victim[0] = 0x00
0x70: fastbin_victim -> fake_libc_chunk -> (main_arena + 0x68)
然后再覆盖fake_libc_chunk 的fd指针使得它指向__malloc_hook附近
我们需要一个有效的malloc size ,在__memalign_hook附近,这通常是一个0x7f开头的地址。
由于__memalign_hook前面都是NULL字节(0x00),我们可以通过错位对齐(misaligned)的chunk,使其被识别为0x70 fastbin的有效尺寸。
这里需要爆破半个字节(四位)因为最后12位是固定的 由于页对齐 但是倒数12到倒数16位,这四个位却不是固定的。
覆盖完之后结果如下:0x70: fastbin_victim -> fake_libc_chunk -> (__malloc_hook - 0x23).
然后malloc(0x60)三次 就可以获得malloc_hook_chunk
阶段2: unsorted bin attack
unsortedbin attack允许我们把main_arena + 0x68 位置的值写到__malloc_hook.
这一步需要8位的爆破
先申请uint8_t* unsorted_bin_ptr = malloc(0x80);
这个大小和fastbin无关,也就不会和前面的块有关,而是进入unsorted bin
malloc(0x30);// 防止合并,同时fastbin一般不会被切割,并且在这里,fastbin已经被打乱了,程序并不知道有一个freed的relative_offset_heap
free(unsorted_bin_ptr)
这里就可以直接开始打unsorted_bin_attack了
我们需要获得__malloc_hook - 0x10的值,这里需要爆破,一样由于页对齐,倒数第四个 4bits需要进行爆破。
然后再malloc(0x80) 这里必须大小完全一致,否则会有链完整性的检查。
再把__malloc_hook 设置到system
也就是把main_arena + 0x68 设置成system
我们之前已经获得了一个malloc_hook_chunk 写入就行 这里需要爆破system在libc里面的地址,并且可能是比较多的。
最后一步是malloc(shell);
house_of_mind_fastbin
通过伪造一个fake non-main arena 来实现任意写入
non-main arena 是除了主分配区之外的动态管理内存的区域 每个新的线程可能会分配自己的堆内存,这就要用到non-main arena
前提:
- 能够分配任意数量的chunks
- 存在一个byte的溢出
- 存在内存泄漏
有两种利用的方式
- 向任意地址写入一个被释放掉的指针
- 向任意地址写入一个大数值
这个漏洞利用的核心就是 non-main arenas在glibc中的使用。
首先了解一下 non-main arena的机制
heap info struct结构
struct _heap_info |
mstate 是 malloc_state结构体指针 指向该堆所属的arena
在 主分配区(main arena) 中,heap_info 不存在,因为主堆是通过 brk 扩展的,而非 mmap。
在 非主分配区(non-main arena) 中,多个 heap_info 可能共享同一个 arena(例如多线程环境下)。
size 记录当前堆的大小,包括heap_info 结构
mprotect_size 表示被mprotect 保护的内存大小
pad用来保证heap_info是内存对齐的 一般不用管。
主分配区 (main_arena)有一个special pointer 非主分配区都在对应的heap的最开头,
#define arena_for_chunk(ptr)
(chunk_non_main_arena (ptr) ? heap_for_ptr (ptr)->ar_ptr : &main_arena)
这个宏显示了怎么从一个chunk的ptr获取arena的位置
这个攻击手法的核心是通过伪造一个虚假的arena 在释放fastbin时通过滥用arena_for_chunk 将指针写入任意位置
流程如下:
- 为 non-main arena 定位一个有效的内存区域。
- 通过连续分配大量堆内存块,最终使堆空间扩展到非主线程专属的 arena 内存区域,从而获得对该 arena 内部数据的控制权。
- 伪造heap_info结构体,用于指定后续作为arena使用的’ar_ptr’
- 利用伪造的arena ,通过fastbin将指针写入’ar_ptr’的非常规内存。
int HEAP_MAX_SIZE = 0x4000000;
int MAX_SIZE = (128*1024) - 0x100;
- malloc(0x1000) 作为伪造的arena
target_loc = fake_arena + 0x28
target_chunk = fake_arena - 0x10 - 准备一个有效的 arena 用于存储fastbin 。chunk的大小会通过system_mem进行验证,确保它不hi太小或者太大,这里只需要一个比fastbin chunk更大的值
fake_arena[0x880] = 0xFF;
fake_arena[0x881] = 0xFF;
fake_arena[0x882] = 0xFF;
接下来计算fake arena 的位置。
uint64_t new_arena_value = (((uint64_t) target_chunk) + HEAP_MAX_SIZE) & ~(HEAP_MAX_SIZE - 1);
作用:
计算一个 对齐到 HEAP_MAX_SIZE 的地址,作为伪造的 arena 的基地址。
uint64_t* fake_heap_info = (uint64_t*) new_arena_value;
作用:
将计算出的对齐地址 new_arena_value 转换为 uint64_t* 指针,表示 伪造的 heap_info 结构。
uint64_t* user_mem = malloc(MAX_SIZE);
如果攻击者希望 切换到非主线程的 arena(如 mmap 分配的堆),可能需要通过大量分配使 main_arena 耗尽空间,从而触发 glibc 分配新的 heap_info 和 arena。
3. while ((long long)user_mem < new_arena_value) {
user_mem = malloc(MAX_SIZE);
}
前面已经计算new_arena_value所在的位置 ,这里用过反复malloc获得目标位置
准备一个 fastbin 大小的堆块(chunk)作为攻击目标
uint64_t* fastbin_chunk = malloc(0x50);
uint64_t* chunk_ptr = fastbin_chunk - 2; // Point to chunk instead of mem
printf(“Fastbin Chunk to overwrite: %p\n”, fastbin_chunk);
4. 填入heap_info信息
fake_heap_info[0] = (uint64_t) fake_arena; // Setting the fake ar_ptr (arena)
chunk_ptr[1] = 0x60 | 0x4; // Setting the non-main arena bit 这一步很关键,它成功让程序认为这玩意是由新的arena 管理的
5. free(fastbin_chunk);
内存布局:
malloc_state {
0x0: mutex等字段
0x8: fastbinsY[0] ← 这是第一个可写位置
…
0x28: fastbinsY[4] ← size=0x60的chunk会写入这里
}
攻击原理:
当释放size=0x60的fastbin chunk时:
glibc会计算fastbin_index(0x60) = 4
写入位置 = arena地址 + 0x8(fastbinsY偏移) + 0x20(4*8字节)
最终写入arena+0x28处
house_of_storm
2.26到2.28需要先填满tcache才能实现此攻击
这个技术通过篡改unsorted bin 和 large bin ,实现向内存中用户指定的地址写入 一个size
如果这个伪造位置的size和分配请求的大小符合 ,就能获得内存块。
因此可以获得任意的内存块!
准备阶段:
准备一个unsorted bin 和 large bin, unsorted bin chunk大小要大于largebin chunk
unsorted_bin = malloc( 0x4e8 );
malloc( 0x18 );//防止合并
寻找需要分配的精确大小:
利用对内存的前’X’字节作为chunk的’size’字段,必须分配一个与这个大小完全匹配的chunk
因此我们需要提取堆地址的高位字节作为大小值,分配一个对应此大小的chunk
这有50%的失败概率 ,如果第四位是1 大小比对将失败。
int shift_amount = get_shift_amount(unsorted_bin);// 计算 unsorted bin的位移量
size_t alloc_size = ((size_t)unsorted_bin) >> (8 * shift_amount);
这两步其实就是说要申请的大小 不知道为啥讲的那么复杂……
如果alloc_size < 0x10 那么直接退出,不进行任何操作。
然后向0x10取整。减去0x10 就是确切的大小了。
alloc_size = (alloc_size & 0xFFFFFFFFE) - 0x10;
检查条件是否符合:
NON_MAIN_ARENA标志位不能被设置。同时即使没设置 ,对于假chunk的内存区域也有要求
或者
设置mmap位 mmap会导致对于分配区一致的检查直接不进行
同时 两种情况都要保证第四位不是1
操作部分:
large_bin = malloc ( 0x4d8 ); // size 0x4e0 前面提到过largebin 要比unsorted bin 偏小
malloc 0x18防止合并
free( large_bin );
free( unsorted_bin )
unsorted_bin = malloc(0x4e8); 整理机制 0x4d8 chunk 会进入large_bin
free( unsorted_bin )
fake_chunk = target - 0x10;
接下来需要溢出漏洞
覆盖unsorted_bin[1] = (size_t)fake_chunk ;
large_bin [1] =(size_t) fakechunk + 8 ;//只需要是一个有效的地址
(( size_t *) large_bin)[3] = (size_t)fake_chunk - 0x18 - shift_amount; 这里通过地址的错位对齐,使得目标位置获得一个合理的大小。
ptr = malloc(alloc_size);
//获得目标位置.
house of gods
“众神之屋”(House of Gods)是一种针对glibc < 2.27版本的竞技场(arena)劫持技术。该技术
允许攻击者对主线程的thread_arena符号进行任意写入操作,从而可以用精心构造的伪造arena
替换原有的main_arena。此漏洞利用方案已通过测试验证 —— deepseek
强制性要求:
- 8次任意大小的内存分配以劫持arena
- 能够控制chunk data的前五个Qword
- 存在对unsorted chunk的use_after_free
- 需要泄露堆地址和libc地址
演示了怎么劫持thread_arena 但不会进一步阐述如何进行任意代码执行。
此技术的完整技术是仅需10到11次内存分配即可实现从零到任意代码执行,但是这个例子并不会展示 .
核心原理 : 通过在main_arena 的 binmap字段(0x85 offset)构造一个堆叠的fakechunk, 利用smallbin或者largebin控制它的size字段,然后借助use_after_free漏洞让这个伪造chunk进入unsorted bin ,
,借此来篡改main_arena.next指针(0x868 offset),使它指向伪造的arena,然后通过unsortedbin attack将narenas变量写成一个大数,,此时只需进行两次大内存(≥0xffffffffffffffc0字节)分配即可触发reused_arena()函数的连续调用
该函数会遍历被破坏的arena链表,最终将thread_arena设置为main_arena.next所指向的伪造arena地址。
开始阶段
申请一些chunk
void *SMALLCHUNK = malloc(0x88); smallbin大小
void *FAST20 = malloc(0x18); fastbin大小
void *FAST40 = malloc(0x38);
free(SMALLCHUNK); smallchunk进入unsorted bin .
这时候。我们可以通过SMALLCHUNK存储的fd和bk进行一次libc的泄露
const uint64_t leak = *((uint64_t*) SMALLCHUNK);
这时候我们需要申请一个chunk,它无法用刚释放的smallchunk满足,因此将申请一个0xa0大小的chunk。
void *INTM = malloc(0x98); 这时候之前的SMALLCHUNK就会移动到smallbin中.
SMALLCHUNK进入smallbin时,会触发mark_bin . 0x855处的binmap初始值变成了0x200,这可以作为一个有效的size字段用来绕过unsorted bin的检查机制。
由于unsorted bin中的部分解链(partial unlinking)过程需要有效的bk指针,幸运的是偏移量0x868处的main_arena.next指针初始指向main_arena自身起始地址。这一特性使得我们能够安全通过解链检查而不会引发段错误。
接下来将通过利用unsorted chunk的use-after-free漏洞(注:原文write-after-free应为笔误),将其从unsorted bin中重新分配。
获取main_arena 空间
- 回收一遍之前的SMALLCHUNK
SMALLCHUNK = malloc(0x88);//这并不是必要的
free(SMALLCHUNK); - 漏洞的利用,这里需要一个简单的use_after_free漏洞.
*((uint64_t*) (SMALLCHUNK + 0x8)) = leak + 0x7f8;
这一步将unsortedbin 定向到binmmap 但是会破坏bin的结构 需要再一次定向进行修复 - *((uint64_t*) (FAST40 + 0x8)) = (uint64_t) (INTM - 0x10); 把FAST40的bk指向一个chunk
- free(FAST20); 这是为了伪造所需的size字段。
- free(FAST40); 伪造bk指针。
- head -> SMALLCHUNK -> binmap -> main-arena -> FAST40 -> INTM 现在的结构.
- 申请一个和binmapsize字段符合的chunk, void *BINMAP = malloc(0x1f8);
- head -> main-arena -> FAST40 -> INTM SMALLCHUNK又重新被整理进smallbin
利用main_arena
main_arena.next
main_arena.system_mem
通过篡改main_arena.next,可以操控arena链表并插入一个伪造arena的地址。完成此操作后,即可触发两次对malloc中reused_arena()函数的调用。
*((uint64_t*) (INTM + 0x8)) = leak - 0xa40;// set INTM’s bk to narenas-0x10.
*((uint64_t*) (BINMAP + 0x20)) = 0xffffffffffffffff;
head -> main-arena -> FAST40 -> INTM -> narenas-0x10;
INTM = malloc(0x98);//unsortedbin attack
这样之后 ,narenas变量就会被设置成unsorted bin head的地址,足以突破现有的arena数量限制,现在开始操作我们之前分配的binmap-chunk中的main_arena.next指针,”写入该字段的地址将成为thread_arena的新取值
*((uint64_t*) (BINMAP + 0x8)) = (uint64_t) (INTM - 0x10);
将main_arena.next设置为任意地址。随后两次调用malloc时,thread_arena将被覆写为相同地址。
malloc(0xffffffffffffffbf + 1); set thread_arena to the address of the current main-arena.
malloc(0xffffffffffffffbf + 1); set thread_arena to the address stored in main_arena.next - our fake arena.
uint64_t fakechunk[4] = { |
*((uint64_t*) (INTM + 0x20)) = (uint64_t) (fakechunk); 这是0x70fastbin的位置。
void *FAKECHUNK = malloc(0x68);
这就操控了目标位置
.
